# 设计方案
# 领域模型
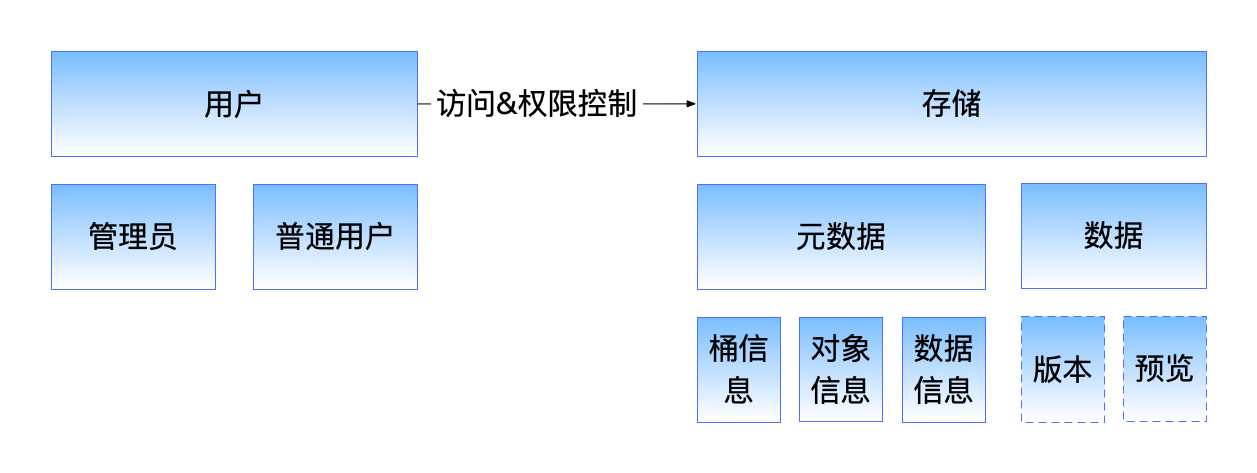
实体包括用户、存储两种,它们之间的关联是访问和权限控制
用户分为管理员和普通用户
存储按类别分为元数据和数据
- 元数据有桶信息、对象信息、数据信息,桶里面用有对象,每个对象信息可以关联数据信息,比如版本和预览的数据等,也可以不关联数据,比如目录和文件对象
# 存储设计
# 关于存储选型
数据部分为什么用自研存储而不是RocksDB?因为LSM类实现存在写放大问题。而元数据部分用关系型数据库存储因为查询和排序比较方便,也可以改用合适的KV存储,后续可以看场景和性能测试而定。
# 默认约定
- 元数据和数据分开存储
提供存储适配器接口,这样你可以随意修改成你想要的实现。
- 按对象大小分类存储
小对象支持打包存储,多个小文件打包成一个数据包上传;大对象分块存储,数据块默认按4MB切块,也即4194304B,读取大对象时,根据数据总大小计算出需要读取多少个块即可,理论上支持无限大的对象(前端因为受到浏览器自带的上传下载功能限制,支持大小受限)。
- 数据只追加不修改(WORM, Write-Once-Read-Many)
这可以简化强一致问题,不再需要引入NRW quorum等算法,不再需要读取多个副本选择更新版本,只需要读取元数据中的最新版本即可,后续实现多副本版可展开讨论。
- 数据引用/秒传(对象级重复数据删除)
校验值满足完整性校验本身就需要提供,现在还能额外支持对象级重复数据删除,秒传的数据引用功能还能够用于云端复制和剪切功能,只需要提供索引(目录信息)即可。OrcaS从一开始就支持秒传,数据独立于元数据,而非依附于元数据(否则后续实现会相对复杂)。
- 支持常见压缩和加密方法
压缩支持snappy、zstd、gzip等、加密支持国密SM4-CBC-PKCS7Padding、AES-256-GCM等,保障数据安全,拥有正确密钥的设备才能在设备端访问数据(全链路)。因为OrcaS设计的是重客户端模式,所以数据压缩加密在设备端完成,也就意味着可以任意选择合适的压缩加密方式。
# 元数据设计
- 一般元数据存储会设计成全路径或者父子对象ID的方式
| 方案 | 优点 | 缺点 |
| 全路径 | 前缀查询,定位较快 | 移动/重命名需要批量修改前缀,层级深的话,占用空间比较多 |
| 父子ID | 移动可以配合秒传/数据引用功能简化 | 需要每一级查询;客户端可能需要维护ID和名称的关系 |
这里我们选择的是父子ID方案,当然也可以在name中放置/来当KV存储使用。
# 【桶信息】
- 桶ID
- 桶名称
- 拥有者
- 桶类型
- 配额
- 使用量,统计所有版本的原始大小
type BucketInfo struct {
ID int64 `borm:"id"` // 桶ID
Name string `borm:"name"` // 桶名称
UID int64 `borm:"uid"` // 拥有者
Type int `borm:"type"` // 桶类型,0: none, 1: normal ...
Quota int64 `borm:"quota"` // 配额
Usage int64 `borm:"usage"` // 使用量,统计所有版本的原始大小
}
2
3
4
5
6
7
8
# 【对象信息】
- 父级的ID
- 对象名称
- 对象大小
- 创建时间
- 修改时间(如果没有,那就是创建时间)
- 对象的类型
- 数据ID
- 扩展信息
type ObjectInfo struct {
ID int64 `borm:"id"` // 对象ID(idgen随机生成的id)
PID int64 `borm:"pid"` // 父对象ID
MTime int64 `borm:"mtime"` // 更新时间,秒级时间戳
DataID int64 `borm:"did"` // 数据ID,如果为0,说明没有数据(新创建的文件,DataID就是对象ID,作为对象的首版本数据)
Type int `borm:"type"` // 对象类型,-1: malformed, 0: none, 1: dir, 2: file, 3: version, 4: preview(thumb/m3u8/pdf)
Name string `borm:"name"` // 对象名称
Size int64 `borm:"size"` // 对象的大小,目录的大小是子对象数,文件的大小是最新版本的字节数
Ext string `borm:"ext"` // 对象的扩展信息
}
2
3
4
5
6
7
8
9
10
# 【数据信息】
- 是否压缩
- 是否加密
- 原始MD5值
- 原始CRC32值
- 前100KB头部CRC32值
- 打包块的ID和偏移位置
type DataInfo struct {
ID int64 `borm:"id"` // 数据ID(idgen随机生成的id)
Size int64 `borm:"size"` // 数据的大小
OrigSize int64 `borm:"o_size"` // 数据的原始大小
HdrCRC32 uint32 `borm:"h_crc32"` // 头部100KB的CRC32校验值
CRC32 uint32 `borm:"crc32"` // 整个数据的CRC32校验值(最原始数据)
MD5 int64 `borm:"md5"` // 整个数据的MD5值(最原始数据)
Cksum uint32 `borm:"cksum"` // 整个数据的CRC32校验值(最终数据,用于一致性审计)
Kind uint32 `borm:"kind"` // 数据状态,正常、损坏、加密、压缩、类型(用于预览等)
PkgID int64 `borm:"pkg_id"` // 打包数据的ID(也是idgen生成的id)
PkgOffset uint32 `borm:"pkg_off"` // 打包数据的偏移位置
}
2
3
4
5
6
7
8
9
10
11
12
PS: 这里的MD5使用的是64位的,刚好可以使用int64存储,以加速匹配时间以及减少存储空间。
添加(pid,name)的唯一索引用于发现同名冲突,这是唯一存在并发控制的地方,这样设计也避免了事务的存在。
数据库字段特意整理成16字节对齐,小整型或者文本类型放到最后,实际测试对空间占用减少有帮助。
如果不想启用秒传功能,也可以不传CRC32、MD5;不需要数据校验功能,也可以不传checksum。
元数据部分就是简单的CRUD,这里用了borm (opens new window)的sqlite分支。
# 树形结构
根对象的ID是0,详见core.ROOT_OID。目录下面是子目录或者文件、文件下面只有版本、版本下面只有预览。
# 同步盘场景
同步盘需要把所有变化的内容都同步到本地,可以用DataID来发现更新(类似版本号),更新时从下往上更新(可以合并),发现时从上往下查找。
# 删除对象
并不像大部分文件系统设计一样,在根目录下放置一个回收站,对象删除会先到回收站,咱们这里直接设计成删除时,把PID翻转成原来的负数,让对象从原来的树形结构中消失(需要同时更新mtime)。这样设计的好处是,列举PID为负数的对象就是被删除的对象,还可以知道原来是从哪里删除的。同时可以避免回收站下,名称冲突问题,但是在同一个目录下,先后删除同样名称的对象两次还是会出现冲突问题,需要后续解决或者仅仅提示错误。
# 数据设计
数据存储方式和Ceph、Swift以及常见对象存储设计类似,对名称做hash,第一级为hash十六进制字符串的最后三个字符,第二级为hash值,第三级为数据名称,数据名称这里我们设置为数据ID_分块序号SN。咱们来分析一下,由于hash的存在,所以即使是同一个数据的多个数据块也不会存储在同一个目录下,三个字母会有4096个组合,也即会均匀分散到四千多个目录里,而第三级的实际名称能在hash发生冲突时解决冲突。单目录下10000个文件索引性能不受影响,文档平均大小在1M(来自某家庭存储产品的实验室数据),单个桶理论能至少存放10TB数据。
// path/<文件名hash的最后三个字节>/hash/<dataID>_<sn>
func toFilePath(path string, bcktID, dataID int64, sn int) string {
fileName := fmt.Sprintf("%d_%d", dataID, sn)
hash := fmt.Sprintf("%X", md5.Sum([]byte(fileName)))
return filepath.Join(path, fmt.Sprint(bcktID), hash[21:24], hash[8:24], fileName)
}
2
3
4
5
6
其中,hash[8:24]是64位MD5十六进制表示的取值部分,hash[21:24]是最后三个字符。
# 举例说明
/tmp/test/27490508603392/14F/B58F53F837AC814F/27490525380709_0
/tmp/test为挂载路径,27490508603392为桶ID,后面为桶内数据存储路径,27490525380709是数据ID,0是SN序号,B58F53F837AC814F是名称27490525380709_0的64位MD5值的是十六进制表示,14F是B58F53F837AC814F的最后三个字符。
# 空对象
空对象不上传,用固定的ID和信息占位。
const EmptyDataID = 4708888888888
func EmptyDataInfo() *DataInfo {
return &DataInfo{
ID: EmptyDataID,
MD5: -1081059644736014743,
Kind: DATA_NORMAL,
}
}
2
3
4
5
6
7
8
9
# 异步写入
这里用了ecache (opens new window)实现了写缓冲队列,在淘汰、覆盖、删除的时候触发刷新磁盘检查,并且每1秒也会强制遍历刷盘,目前来看,优势不是特别明显,需要后续调优。
const interval = time.Second
var Q = ecache.NewLRUCache(16, 1024, interval)
func init() {
Q.Inspect(func(action int, key string, iface *interface{}, bytes []byte, status int) {
// 淘汰、覆盖、删除
if (action == ecache.PUT && status <= 0) || (action == ecache.DEL && status == 1) {
(*iface).(*AsyncHandle).Close()
}
})
go func() {
// manually evict expired items
for {
Q.Walk(func(key string, iface *interface{}, bytes []byte, expireAt int64) bool {
// 遍历过期的item,并且清理
return true
})
time.Sleep(interval)
}
}()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 目录组织
/tmp/test/27490508603392/14F/B58F53F837AC814F/27490525380709_0
# 数据文件
/tmp/test/27490508603392/meta.db # 桶数据库,对象信息和数据信息表
/tmp/test/27490508603392/ # 桶目录
/tmp/test/meta.db # 桶信息表、用户信息表
/tmp/test/ # 存储挂载目录
2
3
4
5
6
# 发号器方案设计
对于ID生成使用的发号器的大致需求:
- 默认单机的,如果是分布式的,可以通过配置redis连接地址来快速支持
- 没有限制ID的生成,不传ID参数默认由服务端生成新的并返回,可以主动生成后传入,和MongoDB类似
- 生成的ID能够随着时间推移,单调递增
并没有使用数据库主键的方案,这有几个方面的考量,一个是后续便于无缝切换为集群版本,多DB存储时不会产生主键冲突;一个是能够自带时间维度的信息。
这里参考MongoDB的对象ID的设计,前半部分是时间戳,后面是实例号和序号,正好和Cassandra的snowflake雪花❄️算法也接近。
基本思路是,用Redis(多节点)或者本地内存缓存ecache (opens new window)(单机)存储每秒每实例的序列号,如果Redis请求发生故障,序列号部分降级为随机数,具体实现见orca-zhang/idgen (opens new window)。
目前设计的是前42位存储秒级时间戳,中间4位存储实例号(可多个节点复用,最多可部署16个独立的发号器),最后18位存储序列号(单“实例”内每秒分配不超过13万个)。由于JavaScript最大可表示的安全数字是 253 – 1,所以需要考虑到精度安全问题,目前idgen能够保证到2090-09-27 13:14:06精度不丢失。
# 接口设计
- 批量写入对象信息,同时可以带部分对象的秒传/秒传预筛选
- 读取对象信息
- 读写数据、随机读取数据的一部分(支持在线播放和在线预览等)
- 列举对象信息:无限加载模式,支持按对象名、对象类型过滤,支持对象名称、大小、时间排序
type ListOptions struct {
Word string // 过滤词,支持通配符*和?
Delim string // 分隔符,每次请求后返回,原样回传即可
Type int // 对象类型,-1: malformed, 0: 不过滤(default), 1: dir, 2: file, 3: version, 4: preview(thumb/m3u8/pdf)
Count int // 查询个数
Order string // 排序方式,id/mtime/name/size/type 前缀 +: 升序(默认) -: 降序
Brief int // 显示更少内容(只在网络传输层,节省流量时有效),0: FULL(default), 1: without EXT, 2:only ID
}
2
3
4
5
6
7
8
定义接口如下:
type Handler interface {
// 传入underlying,返回当前的,构成链式调用
New(h Handler) Handler
Close()
SetOptions(opt Options)
// 设置自定义的存储适配器
SetAdapter(ma MetadataAdapter, da DataAdapter)
// 只有文件长度、HdrCRC32是预Ref,如果成功返回新DataID,失败返回0
// 有文件长度、CRC32、MD5,成功返回引用的DataID,失败返回0,客户端发现DataID有变化,说明不需要上传数据
// 如果非预Ref DataID传0,说明跳过了预Ref
Ref(c Ctx, bktID int64, d []*DataInfo) ([]int64, error)
// sn从0开始,DataID不传默认创建一个新的
PutData(c Ctx, bktID, dataID int64, sn int, buf []byte) (int64, error)
// 只传一个参数说明是sn,传两个参数说明是sn+offset,传三个参数说明是sn+offset+size
GetData(c Ctx, bktID, id int64, sn int, offset ...int) ([]byte, error)
// 上传元数据
PutDataInfo(c Ctx, bktID int64, d []*DataInfo) ([]int64, error)
// 获取数据信息
GetDataInfo(c Ctx, bktID, id int64) (*DataInfo, error)
// Name不传默认用ID字符串化后的值作为Name
Put(c Ctx, bktID int64, o []*ObjectInfo) ([]int64, error)
Get(c Ctx, bktID int64, ids []int64) ([]*ObjectInfo, error)
List(c Ctx, bktID, pid int64, opt ListOptions) (o []*ObjectInfo, cnt int64, delim string, err error)
Rename(c Ctx, bktID, id int64, name string) error
MoveTo(c Ctx, bktID, id, pid int64) error
// 垃圾回收时有数据没有元数据引用的为脏数据(需要留出窗口时间),有元数据没有数据的为损坏数据
Recycle(c Ctx, bktID, id int64) error
Delete(c Ctx, bktID, id int64) error
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
这套接口可以说是整个系统的灵魂所在,未来网络层、多副本、多节点、多集群等都会在这套接口上进行扩展和实现(有可能会有改动和调整)。
OrcaS并没有使用轻客户端、重服务端的方式,而是使用sdk的方式,分摊部分计算和逻辑到客户端完成,从输入端就开始,而不是像平常一样到服务端处理,这样也便于在接口层面做到端到端的统一,对于sdk来说,不需要关心Handler是来自哪一层,包括了那些特性,对sdk来说它们看上去都是一样的。在客户端实现打包和组装、加解密和解压缩逻辑,本地的实现是数据直接写入存储;远端的实现是数据通过rpc传输,调用方无法感觉到差别。
# “特别”的设计
Ref、Put关于负数ID的设计:
Ref秒传接口返回的ID如果有负数,说明在同一批中,找到了相同的数据,以下标反码的方式指出,比如引用了第0个元素,那返回就是^0,刚好是负数的最小值,以此类推;而在Put接口上传对象信息时,PID字段同样可以引用还未生成ID的其他对象,以实现一次批量创建一批有父子关系的对象的效果。
# SDK配置
type Config struct {
DataSync bool // 断电保护策略(Power-off Protection Policy),强制每次写入数据后刷到磁盘
RefLevel uint32 // 秒传级别设置:OFF(默认) / FULL: Ref / FAST: TryRef+Ref
PkgThres uint32 // 打包个数限制,不设置默认100个
WiseCmpr uint32 // 智能压缩,根据文件类型决定是否压缩,取值见core.DATA_CMPR_MASK
EndecWay uint32 // 加密方式,取值见core.DATA_ENDEC_MASK
EndecKey string // 加密KEY,SM4需要固定为16个字符,AES256需要大于16个字符
DontSync string // 不同步的文件名通配符(https://pkg.go.dev/path/filepath#Match),用分号分隔
Conflict uint32 // 同名冲突解决方式,COVER:合并覆盖 / RENAME:重命名 / THROW:报错 / SKIP:跳过
NameTmpl string // 重命名尾巴,"%s的副本"
WorkersN uint32 // 并发池大小,不小于16
}
2
3
4
5
6
7
8
9
10
11
12
PS:别怀疑,我有强迫症,连配置名字都要对齐。
# 上传逻辑
# 单个文件上传过程描述
- 读取头部CRC32和大小,来预检查是否可能秒传(可以用阈值来优化小对象直接跳过预检查)
- 没有可能匹配的直接上传
- 有可能匹配的,计算整个对象的MD5和CRC32后继续尝试秒传
- 秒传失败,转普通上传
# 秒传的实现逻辑
如果两个数据的哈希值和长度完全相同,那我们认为他们是完全等同的,那么对象可以使用相同的数据信息(同样的数据ID),为了防止引用过程中可能被同时删除的问题,我们引入一个相对较长的时间窗口即可,需要同时提供MD5和CRC32,是因为存在哈希冲突和漏洞问题。MD5算法选择64位的来减少空间使用,提高匹配效率,虽然这样会增加冲突概率,但是同时会有CRC32存在防止冲突。由于是批量完成的,这里我们用到了小的临时表和元数据表做JOIN的方式实现。
// 创建临时表
db.Exec(`CREATE TEMPORARY TABLE ` + tbl + ` (o_size BIGINT NOT NULL,
h_crc32 UNSIGNED INT NOT NULL,
crc32 UNSIGNED INT NOT NULL,
md5 BIGINT NOT NULL
)`)
// 把待查询数据放到临时表
if _, err = b.Table(db, tbl, c).Insert(&d,
b.Fields("o_size", "h_crc32", "crc32", "md5")); err != nil {
return nil, err
}
var refs []struct {
ID int64 `borm:"max(a.id)"`
OrigSize int64 `borm:"b.o_size"`
HdrCRC32 uint32 `borm:"b.h_crc32"`
CRC32 uint32 `borm:"b.crc32"`
MD5 int64 `borm:"b.md5"`
}
// 联表查询
if _, err = b.Table(db, `data a, `+tbl+` b`, c).Select(&refs,
b.Join(`on a.o_size=b.o_size and a.h_crc32=b.h_crc32 and
(b.crc32=0 or b.md5=0 or (a.crc32=b.crc32 and a.md5=b.md5))`),
b.GroupBy("b.o_size", "b.h_crc32", "b.crc32", "b.md5")); err != nil {
return nil, err
}
// 删除临时表
db.Exec(`DROP TABLE ` + tbl)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 核心逻辑描述
这里用到了层序遍历,用一个slice当作队列来实现目录对象的进出队,列举到目录时,就把目录放到队列尾部,如果队列不为空,就读取目录下的子目录和文件。
// 定义一个slice队列
q := []elem{{id: dirIDs[0], path: lpath}}
// 遍历本地目录
for len(q) > 0 {
rawFiles, _ := ioutil.ReadDir(q[0].path)
for _, fi := range rawFiles {
if fi.IsDir() {
dirs = append(dirs, fi)
} else {
// 上传文件
}
}
// 上传dirs后得到子目录的ID
ids, _ := osi.h.Put(c, bktID, dirs)
// 组装dirElems
//deal with `dirElems`
// 弹出第一个处理完成的元素,放入子目录元素
q = append(q[1:], dirElems...)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 秒传
文件上传涉及到秒传的部分用到了分治法,由于秒传有三个级别,预秒传得到的结果是秒传或者普通上传,秒传得到的结果是只传对象信息或普通上传,普通上传是上传数据、上传数据信息、上传对象信息。所以设计成了配置复用状态机(同样三个状态,但是语义不同)的形式,预秒传得到的结果分两部分迁移到秒传或者普通上传,秒传失败的结果迁移到普通上传。最不理想情况下,最多递归嵌套三层,没有爆栈风险,也即预秒传失败->秒传失败->普通上传。
ids, _ := osi.h.Ref(c, bktID, d)
for i, id := range ids {
if id > 0 {
// 成功部分
f1 = append(f1, f[i])
d1 = append(d1, d[i])
} else {
// 失败部分
f2 = append(f2, f[i])
d2 = append(d2, d[i])
}
}
// 成功部分到秒传
osi.uploadFiles(c, bktID, f1, d1, dp, FULL, doneAction|HDR_CRC32)
// 失败部分到普通上传
osi.uploadFiles(c, bktID, f2, d2, dp, OFF, doneAction|HDR_CRC32)
// 详见:https://github.com/orcastor/orcas/blob/master/sdk/data.go#L360
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
文件读取这里还有一个优化是每次会告知下一次调用,上一次已经准备好了哪些数据,下一层不再需要读取和计算了。主要是hdrCRC32+文件类型、CRC32、MD5三部分,这样最差情况也只需要读取文件两次+一个头部。
// PS:需要进行秒传操作,读取完整文件,但是标记HDR_CRC32已经读取过了
osi.uploadFiles(c, bktID, f1, d1, dp, FULL, doneAction|HDR_CRC32)
2
# 压缩
在读取头部CRC32的同时,如果开启压缩,这里会根据文件类型判断是否命中压缩率较高的文件类型(目前设置的jpg、png、常见压缩格式),而自动取消压缩。(浪费CPU并且压缩效果很差或者可能会负压缩)
// 如果开启智能压缩,检查文件类型确定是否要压缩
if l.cfg.WiseCmpr > 0 {
kind, _ := filetype.Match(buf)
if kind == filetype.Unknown { // 多媒体、存档、应用
// 不在黑名单里,开启压缩
l.d.Kind |= l.cfg.WiseCmpr
if l.cfg.WiseCmpr&core.DATA_CMPR_SNAPPY != 0 {
l.cmpr = &archiver.Snappy{}
} else if l.cfg.WiseCmpr&core.DATA_CMPR_ZSTD != 0 {
l.cmpr = &archiver.Zstd{}
} else if l.cfg.WiseCmpr&core.DATA_CMPR_GZIP != 0 {
l.cmpr = &archiver.Gz{}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
或者小文件在压缩后数据反而变大了,关闭压缩。
// 如果压缩后更大了,恢复原始的
if l.d.OrigSize < PKG_SIZE {
if l.cmprBuf.Len() >= len(buf) {
l.d.Kind &= ^core.DATA_CMPR_MASK
cmprBuf = buf
} else {
cmprBuf = l.cmprBuf.Bytes()
}
l.cmprBuf.Reset()
}
2
3
4
5
6
7
8
9
10
如果配置中开启了加密压缩,先压缩后加密(最终数据的尺寸更小,占用空间更少)即可。
// 上传数据
if l.action&UPLOAD_DATA != 0 {
// 压缩
var cmprBuf []byte
if l.d.Kind&core.DATA_CMPR_MASK == 0 {
cmprBuf = buf
} else {
l.cmpr.Compress(bytes.NewBuffer(buf), &l.cmprBuf)
cmprBuf = l.cmprBuf.Next(PKG_SIZE)
}
if cmprBuf != nil {
// 加密
encodedBuf, _ := l.encode(cmprBuf)
}
// 上传encodedBuf...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 打包
对于小文件来说,还有一个打包上传的优化逻辑,批量上传文件时,先按文件大小进行排序,如果打包还有足够的空间并且个数没有超过,就放置到打包里,上传后,数据信息记录的是打包的ID和偏移位置。
func (dp *dataPkger) Push(c core.Ctx, h core.Handler,
bktID int64, b []byte, d *core.DataInfo) (bool, error) {
off := dp.buf.Len()
if off+len(b) > PKG_SIZE || len(dp.infos) >= int(dp.thres) || len(b) >= PKG_SIZE {
return false, dp.Flush(c, h, bktID)
}
// 填充内容
dp.buf.Write(b)
// 记录偏移
d.PkgOff = off
// 记录下来要设置打包数据的数据信息
dp.infos = append(dp.infos, d)
return true, nil
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 同名冲突
关于对象重名冲突,一共有四种模式,合并覆盖、重命名、报错、跳过,其中报错和跳过比较简单,发现有同名文件创建失败以后,前者报错,后者忽略错误.
switch osi.cfg.Conflict {
case COVER: // 合并或覆盖
// ...
case RENAME: // 重命名
// ...
case THROW: // 报错
for i := range ids {
if ids[i] <= 0 {
return ids, fmt.Errorf("remote object exists, pid:%d, name:%s", o[i].PID, o[i].Name)
}
}
case SKIP: // 跳过
break
}
2
3
4
5
6
7
8
9
10
11
12
13
14
合并覆盖,尝试获取原来的对象ID,如果是文件对象的,再创建一个版本。
var vers []*core.ObjectInfo
for i := range ids {
// 如果创建失败
if ids[i] <= 0 {
// 获取原来的对象ID
ids[i], err = osi.Path2ID(c, bktID, o[i].PID, o[i].Name)
// 如果是文件,需要新建一个版本,版本更新的逻辑需要jobs来完成
if o[i].Type == core.OBJ_TYPE_FILE {
vers = append(vers, &core.ObjectInfo{....})
}
}
}
if len(vers) > 0 {
osi.h.Put(c, bktID, vers) // 上传新版本
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
如果是重命名相对来说会复杂一些,会先用给定的模版直接尝试创建一个副本,如果还是报错,会先查看除了本身和副本个数cnt,然后会在三个方向上尝试,最差情况会找cnt次(也即刚好全部符合我们的查找序列),正常顺序情况下,只会尝试2次,目前的实现参考的是MacOSX的实现,也即序列为test、test的副本、test的副本2、test的副本3...,实际测试MacOSX的性能很差,在副本已经存在1万个时,创建一个文件需要几秒,可猜测是简单顺序尝试的。
var rename []*core.ObjectInfo
for i := range ids {
// 需要重命名重新创建
if ids[i] <= 0 {
// 先直接用NameTmpl创建,覆盖大部分场景
rename = append(rename, osi.getRename(o[i], 0))
}
}
// 需要重命名重新创建
if len(rename) > 0 {
ids2, _ := osi.h.Put(c, bktID, rename)
for i := range ids2 {
if ids2[i] > 0 {
// 创建成功的,记录一下ID
continue
}
// 还是失败,用NameTmpl找有多少个目录,然后往后一个一个尝试
_, cnt, _, _ := osi.h.List(c, bktID, rename[i].PID, core.ListOptions{
Word: rename[i].Name + "*",
})
// 假设有 test、test的副本、test的副本2,cnt为2
for j := 0; j <= int(cnt/2)+1; j++ {
// 先试试个数后面一个,正常顺序查找,最大概率命中的分支
if ids[m[i]], err = osi.putOne(c, bktID,
osi.getRename(o[i], int(cnt)+j)); err == nil {
break
}
// 从最前面往后找
if ids[m[i]], err = osi.putOne(c, bktID,
osi.getRename(o[i], j)); err == nil {
break
}
// 从cnt个开始往前找
if ids[m[i]], err = osi.putOne(c, bktID,
osi.getRename(o[i], int(cnt)-1-j)); err == nil {
break
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# 下载逻辑
下载逻辑比较简单,和上传类似,只是列举本地目录改成了云端目录,列举目标对象并下载到本地。
// 遍历远端目录
q := []elem{{id: id, path: path}}
for len(q) > 0 {
o, _, _, _ := osi.h.List(c, bktID, q[0].id, core.ListOptions{
Order: "type",
}) // 伪代码,实际还要处理delim,一次获取一批,直到获取不到为止
for _, x := range o {
switch x.Type {
case core.OBJ_TYPE_DIR:
// 下载目录
case core.OBJ_TYPE_FILE:
// 下载文件
}
}
// 弹出第一个元素
q = q[1:]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
如果对象有多个版本的,下载最新版本(如果后续支持快照的,需要找到指定快照ID的版本);如果是空数据,只创建文件;如果是大文件,按SN递增下载多个数据块(由于解密解压都是流式的,所以无法简单优化,对于未加密压缩的大文件,可以考虑优化成多协程下载以提高下载速度)。